





















































































SCORE DE COURSE – COMMENT ÇA FONCTIONNE
Le Score de Course mesure la qualité de votre performance au sein d’une seule course, plutôt que de comparer directement les temps d’arrivée. L’Index UTMB est ensuite construit en combinant plusieurs Scores de Course issus de différentes courses et catégories.
UNE MÉTHODE DE CALCUL OBJECTIVE ET COHÉRENTE
Convertir votre performance en un score de course
Cette méthode garantit que les scores sont objectifs, comparables entre les courses et indépendants des conditions extérieures du jour. Que la course se déroule par temps idéal ou dans des conditions difficiles, une performance forte obtient le score qu’elle mérite — car tous les coureurs sont mesurés par rapport au même peloton le même jour. Le résultat est une course juste, cohérente et significative pour chaque finisher.
Construire votre Index UTMB
Votre Score de Course contribue à votre Index UTMB. Course après course, il constitue une référence mondiale cohérente de votre performance au fil du temps.

4 étapes pour calculer les Scores de Course
Chaque résultat de course passe par les quatre étapes suivantes pour calculer le Score de Course. Pour chaque course, le système suit exactement ces étapes :
1 - RECHERCHE DE COURSES SIMILAIRES
Quelles courses passées dans la base de données peuvent nous fournir des informations utiles sur cette course spécifique ? Nous analysons toute la base de données et ne sélectionnons que les courses qui respectent deux critères simples :
Temps : La course doit avoir eu lieu au cours des 50 derniers mois (environ 4 ans et 2 mois).
Effort : Nous convertissons distance + dénivelé en une valeur unique d’« effort ». La course doit présenter au moins 65 % de l’effort de la course actuelle.
Il n’y a pas de limite supérieure — les courses plus longues ou plus difficiles sont tout de même incluses.
Ces courses sélectionnées constituent la base de toute l’analyse suivante.
2 - CALCUL DU SCORE ATTENDU POUR CHAQUE COUREUR
Nous prédisons la performance que chaque coureur devrait réaliser dans cette course en nous basant sur ses résultats passés pertinents.En termes simples : « Sur la base de ses meilleures performances récentes dans des conditions similaires, quel score pouvons-nous réalistement (mais de manière optimiste) attendre de ce coureur aujourd’hui ? »
Comment nous estimons ce score attendu
Pour chaque coureur nous :
- Utilisons uniquement les résultats passés qui sont pertinents en termes de temps et d’effort (issus de l’étape 1)
- Appliquons une pondération basée sur la similarité de la course (distance + dénivelé) et la récence
- Sélectionnons jusqu’aux 5 meilleures performances pondérées
- Ignorons toute course où le coureur a réalisé une performance nettement inférieure à son niveau habituel
À partir de ces résultats, nous calculons un score attendu par coureur.
Score de confiance
Parce que les scores attendus peuvent varier en fiabilité, nous calculons également un score de confiance basé sur :
- Expérience : nombre de résultats passés pertinents
- Pertinence : similarité de ces courses
- Variabilité : constance des performances
- Récence : ancienneté des courses
Important : Ces scores attendus et valeurs de confiance ne sont utilisés que pour le calcul de cette course et ne sont pas reliés à l’Index UTMB global du coureur.
3 - SÉLECTION DES COUREURS
Nous voulons les données les plus fiables possibles pour représenter l’ensemble du peloton.
Nous disposons maintenant d’un score attendu et d’une valeur de confiance pour de nombreux coureurs, mais nous ne les utilisons pas tous.
Nous créons plutôt un groupe raffiné en :
- Supprimant les valeurs aberrantes les plus lentes (tout coureur ayant mis plus de deux fois le temps du vainqueur).
- Conservant les coureurs ayant les scores de confiance les plus élevés.
- Veillant à ce que le groupe inclue toujours un mélange de profils de coureurs : principalement des athlètes de haut niveau, plus un petit nombre de coureurs amateurs.
Le principe directeur est simple : une quantité moindre de données de haute qualité est plus utile qu’une grande quantité de données de faible qualité. À la fin de cette étape, nous disposons d’un ensemble propre et équilibré de coureurs, chacun avec son score attendu et son score de confiance.
4 - RÉGRESSION (CRÉATION DU MODÈLE SPÉCIFIQUE À LA COURSE)
Transformer les données en score
Nous transformons maintenant les performances réelles des coureurs sélectionnés en une formule de scoring personnalisée pour cette course exacte. Pour chaque coureur de notre groupe raffiné, nous disposons de trois informations :
- Sa vitesse réelle de course (en km/h)
- Son score attendu (issu de l’étape 2)
- Sa confiance (issue de l’étape 2)
Ces données sont représentées sur un graphique :
Axe horizontal = vitesse de course (km/h)
Axe vertical = score attendu
Couleur de chaque point = confiance (plus foncé = confiance plus faible, jaune plus clair = confiance plus élevée)
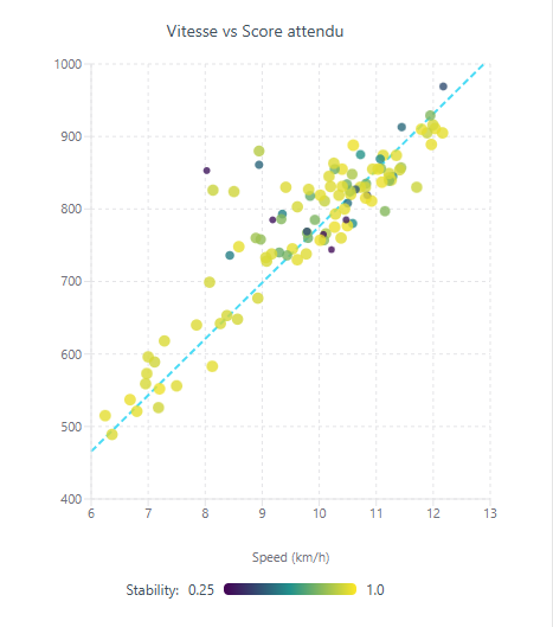
Nous effectuons ensuite une régression asymétrique pondérée. En langage clair, cela signifie que nous ajustons une droite à travers les points, mais avec deux améliorations importantes qui rendent le modèle à la fois juste et précis :
- Pondération par confiance: Les coureurs ayant une confiance plus élevée tirent la droite plus fortement vers eux. Cela nous permet d’utiliser davantage de données tout en priorisant les coureurs les plus fiables.
- Ajustements spécifiques à la course : La droite est également légèrement ajustée à l’aide de trois caractéristiques objectives de la course : pente moyenne du terrain, altitude moyenne et niveau global de compétition.
De la régression au score Le résultat est une formule mathématique simple et unique à cette course : Score Final = Coefficient × Vitesse de Course (km/h) Ce coefficient est différent pour chaque course car chaque course possède un terrain et des conditions différents.
Tableau de conversion exemple (issu d’une vraie course) :
| Vitesse (km/h) | Score |
|---|---|
| 12.2 | 950 |
| 11.6 | 900 |
| 10.3 | 800 |
| 9.7 | 750 |
| 9.0 | 700 |
| 7.7 | 600 |
| 6.4 | 500 |
Vous pouvez visualiser cela sur le graphique:
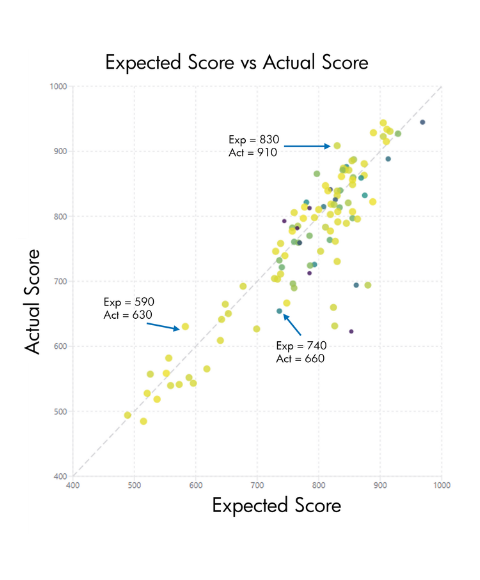
Tracez une ligne horizontale à n’importe quel score attendu (par exemple 900), voyez où elle croise la droite de régression : cette vitesse devient celle qui rapporte exactement 900 points dans cette course.
POURQUOI CETTE MÉTHODE EST-ELLE JUSTE ?
Tous les coureurs d’une course partagent les mêmes conditions le même jour. Le modèle s’ajuste automatiquement à la difficulté de la course :
- Conditions rapides → tout le monde court plus vite
- Conditions lentes → tout le monde court plus lentement
Le score reste cohérent dans les deux scénarios.

