





















































































SCORE DE CARRERA – CÓMO FUNCIONA
El Score de Carrera mide la calidad de tu rendimiento dentro de una sola carrera, en lugar de comparar directamente los tiempos de llegada. El Index UTMB se construye entonces combinando múltiples Scores de Carrera de diferentes carreras y categorías.
UN MÉTODO DE CÁLCULO OBJETIVO Y CONSISTENTE
Convertir tu rendimiento en un score de carrera
Convertir tu rendimiento en un score de carreraEste método garantiza que los scores sean objetivos, comparables entre carreras e independientes de las condiciones externas del día. Ya sea que la carrera se corra con tiempo ideal o en condiciones difíciles, un buen rendimiento obtiene el score que merece — porque todos los corredores se miden contra el mismo pelotón el mismo día. El resultado es una carrera justa, consistente y significativa para cada finisher.
Construyendo tu Index UTMB
Tu Score de Carrera contribuye a tu Index UTMB. Carrera tras carrera, construye una referencia global consistente de tu rendimiento a lo largo del tiempo.

4 pasos para calcular los Scores de Carrera
Cada resultado de carrera pasa por los siguientes cuatro pasos para calcular el Score de Carrera. Para cada carrera, el sistema sigue exactamente estos pasos:
1 - BÚSQUEDA DE CARRERAS SIMILARES
¿Qué carreras pasadas de la base de datos pueden darnos información útil sobre esta carrera específica? Analizamos toda la base de datos y seleccionamos solo las carreras que cumplen dos criterios sencillos :
Tiempo : La carrera debe haberse celebrado en los últimos 50 meses (aproximadamente 4 años y 2 meses).
Esfuerzo : Convertimos distancia + desnivel en un único valor de «esfuerzo». La carrera debe tener al menos el 65 % del esfuerzo de la carrera actual.
No hay límite superior — las carreras más largas o más duras se incluyen igualmente.
Estas carreras seleccionadas constituyen la base del resto del análisis.
2 - CÁLCULO DEL SCORE ESPERADO PARA CADA CORREDOR
Predecimos cómo debería rendir cada corredor en esta carrera basándonos en sus resultados pasados relevantes. En términos sencillos: «Basándonos en sus mejores performances recientes en condiciones similares, ¿qué score podemos esperar de manera realista (pero optimista) que este corredor logre hoy?»
Cómo estimamos este score esperado
Para cada corredor :
- Usamos solo resultados pasados que son oportunos y relevantes en esfuerzo (del Paso 1)
- Aplicamos una ponderación basada en la similitud de la carrera (distancia + desnivel) y la recencia
- Seleccionamos hasta las 5 mejores performances ponderadas
- Ignoramos cualquier carrera en la que el corredor haya rendido dramáticamente peor que su nivel habitual
De estos resultados calculamos un score esperado por corredor.
Score de confianza
Dado que los scores esperados pueden variar en fiabilidad, también calculamos un score de confianza basado en :
- Experiencia: número de resultados pasados relevantes
- Relevancia: similitud de esas carreras
- Variabilidad: consistencia de las performances
- Recencia: lo recientes que fueron las carreras
Importante: Estos scores esperados y valores de confianza se utilizan solo para el cálculo de esta carrera y no están conectados con el Index UTMB global del corredor.
3 - SELECCIÓN DE CORREDORES
Queremos los datos más fiables posibles para representar todo el pelotón.
Ahora tenemos un score esperado y un valor de confianza para muchos corredores, pero no los usamos todos.
En su lugar creamos un grupo refinado :
- Eliminando los valores atípicos más lentos (cualquier corredor que tardó más del doble que el ganador).
- Conservando los corredores con los scores de confianza más altos.
- Asegurándonos de que el grupo siga incluyendo una mezcla de tipos de corredores: principalmente atletas de élite, más un pequeño número de corredores aficionados.
El principio rector es sencillo: una menor cantidad de datos de alta calidad es más útil que una gran cantidad de datos de baja calidad. Al final de este paso tenemos un conjunto limpio y equilibrado de corredores, cada uno con su score esperado y su score de confianza.
4 - REGRESIÓN (CREACIÓN DEL MODELO ESPECÍFICO DE LA CARRERA)
Convertir los datos en un score
Ahora convertimos las performances reales de los corredores seleccionados en una fórmula de puntuación personalizada para esta carrera exacta. Para cada corredor de nuestro grupo refinado disponemos de tres datos :
- Su velocidad real de carrera (en km/h)
- Su score esperado (del Paso 2)
- Su confianza (del Paso 2)
Estos se muestran en un gráfico:
Eje horizontal = velocidad de carrera (km/h)
Eje vertical = score esperado
Color de cada punto = confianza (más oscuro = menor confianza, amarillo más brillante = mayor confianza)
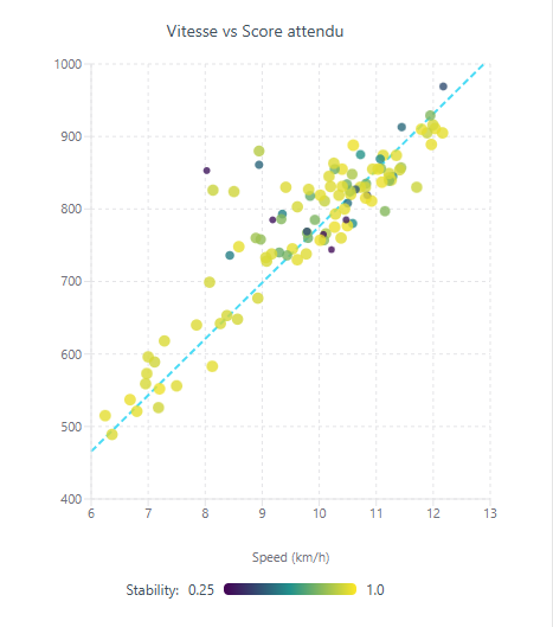
Realizamos entonces una regresión asimétrica ponderada. En lenguaje claro, esto significa que ajustamos una línea recta a través de los puntos, pero con dos mejoras importantes que hacen que el modelo sea justo y preciso :
- Ponderación por confianza: Los corredores con mayor confianza tiran más fuertemente de la línea hacia ellos. Esto nos permite usar más datos mientras priorizamos a los corredores más fiables.
- Ajustes específicos de la carrera: La línea también se ajusta suavemente utilizando tres características objetivas de la carrera: pendiente media del terreno, altitud media y nivel general de competencia.
De la regresión al score El resultado es una fórmula matemática sencilla y única para esta carrera: Score Final = Coeficiente × Velocidad de Carrera (km/h) Este coeficiente es diferente para cada carrera porque cada carrera tiene un terreno y unas condiciones diferentes.
Tabla de conversión de ejemplo (de una carrera real) :
| Velocidad (km/h) | Score |
|---|---|
| 12.2 | 950 |
| 11.6 | 900 |
| 10.3 | 800 |
| 9.7 | 750 |
| 9.0 | 700 |
| 7.7 | 600 |
| 6.4 | 500 |
Puedes visualizarlo en el gráfico:
Dibuja una línea horizontal en cualquier score esperado (p. ej. 900), mira dónde cruza la línea de regresión y esa velocidad se convierte en la velocidad que vale exactamente 900 puntos en esta carrera.
¿POR QUÉ ESTE MÉTODO ES JUSTO?
Todos los corredores de una carrera comparten las mismas condiciones el mismo día. El modelo se ajusta automáticamente a la dificultad de la carrera :
- Condiciones rápidas → todos corren más rápido
- Condiciones lentas → todos corren más lento
El score se mantiene consistente en ambos escenarios.

